
 office2021 正式版
office2021 正式版 Office 2021 LTSC版
Office 2021 LTSC版 搜狗输入法电脑版
搜狗输入法电脑版 Adobe Acrobat PRO DC最新订阅版
Adobe Acrobat PRO DC最新订阅版 苹果iTunes官方正版
苹果iTunes官方正版 PDF Shaper Professional破解版
PDF Shaper Professional破解版 极品五笔输入法2.2最新版
极品五笔输入法2.2最新版 搜狗五笔输入法最新版
搜狗五笔输入法最新版 手心输入法官方PC版
手心输入法官方PC版 7-Zip解压软件电脑版
7-Zip解压软件电脑版







编辑点评:
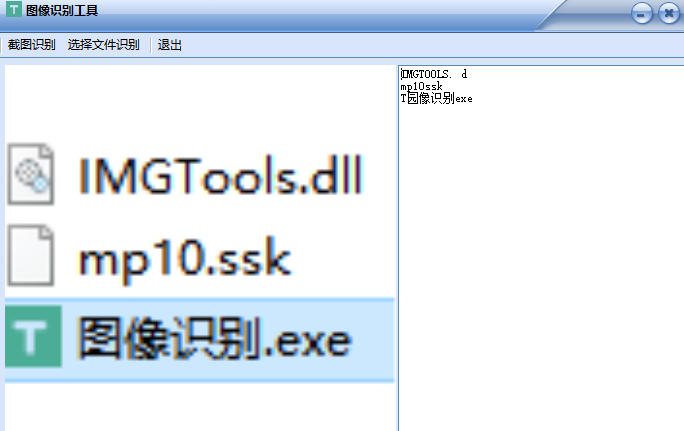
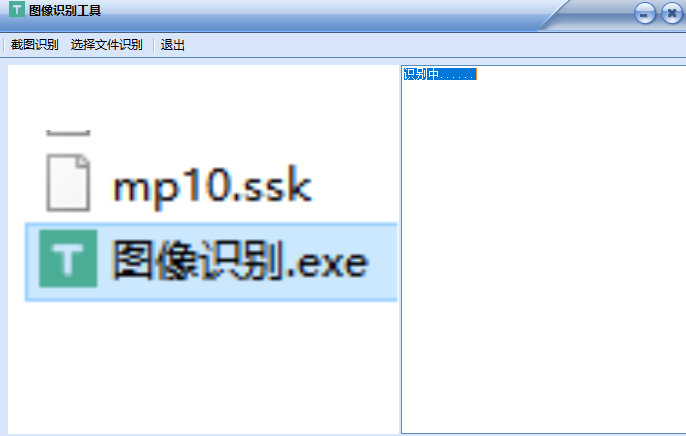
图像识别工具是一款简易的OCR图像识别软件,软件支持本地图像识别以及截图识别两种方式,识别速度快,准确率高,能够有效的为用户提供帮助,使用起来非常方便,欢迎大家下载使用!

软件介绍
coco截图转文字识别器破解版能将图片转换成文字的软件,coco截图转文字识别器官方版可以一键快速截图,转换图片内文字图像为文字信息,非常适合将文件扫描件转换成文档资料。
软件功能
核心功能:快速截取图像,把图像里的文字转换成文本文字(txt、doc等文本格式)。
重点1:“直接截取图像”的意思是,像QQ截图一样,直接截取当前屏幕的图像,极其方便!
重点2:这是本软件,优于市面上所有图像文字转换文本文字软件的,最大特征。
重点3:本软件支持快捷方式截图,能够像QQ使用快捷键一样,快键选择识别区域,这是网络上卖的其它软件所不具有的。
OCR的历史背景
光学文字识别的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以同样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局作区域分信的作业;也因此至今邮政编码一直是各国所倡导的地址书写方式。
20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。中国在OCR技术方面的研究工作起步较晚,在70年代才开始对数字、英文字母及符号的识别进行研究,70年代末开始进行汉字识别的研究,到1986年汉字识别的研究进入一个实质性的阶段,不少研究单位相继推出了中文OCR产品.早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。同时,由于硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。
1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。
进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。其中以OCR为科技核心的云脉技术不断创新进取,研发了一系列OCR软件产品,并且运用在医院,学校,企业等各大市场。
零代码、自动化、定制训练文字识别 百度EasyDL全新发布OCR自训练平台
OCR(文字识别)技术是最早应用于企业降本增效的 AI 方向之一,如今已逐渐下沉为企业智能化升级的一项重要基础设施能力。10月29日,百度智能云线上线下同期举办了TechDay OCR技术创新沙龙,深度分享OCR产品矩阵、功能、应用案例等最新进展,并重磅全新发布EasyDL OCR自训练平台。泰康保险集团、北京融汇金信等企业伙伴在现场分享了OCR在企业内的应用经验和心得。百度智能云OCR产品为企业打造了技术领先、类型丰富同时支持便捷自定制的解决方案,已广泛应用于金融服务、财税报销、快递物流、法律政务、交通出行、教育培训、内容审核等全行业领域,加快推动企业实现产业智能化升级。
业界首发EasyDL OCR自训练平台,低成本满足OCR定制化需求
近年来,OCR的识别能力不断突破,逐渐在更加复杂的数字化场景发挥作用,有效降低信息提取和录入的人力成本,帮助企业专注于上层业务应用。与此同时,企业对于OCR识别模型定制化的需求日益旺盛,包括OCR在特定场景下是否有高精度识别效果、能否高效响应自身业务需求、是否能在模型训练过程中保证数据安全,以上三点成为行业共性诉求。
为满足企业快速定制OCR识别模型的诉求,EasyDL OCR自训练平台应运而生。据介绍,EasyDL OCR 自训练平台具有两大核心产品功能,即自动训练OCR和定制化训练OCR;同时具备三大产品特性,包括内置成熟OCR技术方案,预置经过真实业务检验的多种自动化机制,如智能标注、自动数据预处理、虚拟数据生成等,同时还开放了调参能力,满足多种场景OCR模型定制训练需求,保证高准确率;可视化模型训练,预置领先的OCR算法,可实现零门槛模型训练,高效响应业务需求;支持本地私有化部署,数据无需出厂,有效保障数据安全。
会上,EasyDL OCR产品负责人还分别演示了自动化训练OCR和定制化训练OCR模型训练过程,并在最后总结了适合应用的不同场景和优势。
具体而言,自动化训练OCR每个版式仅需1张训练图片,“智能标注”功能支持快速标注关键字段,显著提升标注效率,系统自动完成模板分类,可应用于版式多样、识别特定字段、图像质量统一的场景,同时模型重训功能支持新增版式的快速扩充。定制化训练OCR则具有数据自动生成能力,可模拟各类真实场景中复杂数据状况,如模糊、变形、缺角等,少量标注数据即可获得更高的识别准确率,可应用于版式固定、全字段识别、图片质量复杂的场景。
百度OCR“技术+产品+应用”行业领先,助力企业智能化升级
百度OCR是国内应用最广泛的文字识别服务,依托业界领先的深度学习技术和海量优质数据,提供多场景、多语种、高精度的文字检测与识别服务,并针对图片模糊、倾斜、翻转等情况进行深度优化,鲁棒性强,多项ICDAR指标居世界第一,通用、主流卡证识别准确率高达99%。
而其背后正是由百度AI核心技术引擎――百度大脑支撑,如今升级到6.0的百度大脑已成为AI新型基础设施。从基础层的算力、数据、飞桨深度学习平台,到感知层的语音、视觉、AR/VR,再到认知层的语言与知识,以及平台层的AI平台与生态,百度大脑始终保持核心技术持续领先,不断夯实“软硬一体AI大生产平台”,并通过百度智能云整合输出产品服务,加速产业智能转型升级。截至目前,百度大脑已经开放了273项AI能力,凝聚超过230万开发者,培养了超过100万AI人才,在众多行业领域落地应用,推动了中国AI技术研发、实践应用与生态建设。
产业智能化升级一个核心前提就是,信息数字化和结构化。OCR作为最早应用于企业效率提升的AI方向之一,显著提升了信息提取和录入的效率,实现了信息处理的“电子化”、“自动化”,为上层业务应用提供有力支撑。
据现场介绍,百度OCR技术经过多年沉淀和实践打磨,在多项行业竞赛评比当中持续摘得桂冠。例如:2019年从90多支参赛队伍中脱颖而出,获得中国最高等级商业领域人工智能技术竞赛唯一A级别证书;在OCR领域最具影响力的ICDAR 19 MLT (多语种task)榜单当中获得文字检测领域世界冠军;。同时,百度OCR也在不断推进算法创新和突破,引领行业技术发展,例如:发布了业界最大的中文OCR数据集,首次提出端到端OCR-部分监督算法End2End-PSL,实现精标数据+弱标数据的混合训练,克服精标数据成本高问题,使得标注成本降低至1/90。
依托百度大脑领先的深度学习技术,百度OCR已开放全系列50多款产品,不仅可以实现通用场景的文字识别,还可满足各类垂直场景的信息电子化、结构化识别需求,例如财务票据识别、医疗票据识别、教育场景的公式识别和试卷识别等等。
打破封闭研发生态,积极赋能企业在具体场景落地
作为保险医疗领域的代表,泰康保险集团科技研究院、图文分析实验室负责人刘兴旺在会上表示:“如何提高理赔效率,降低成本成为各大保险公司非常关注的一点。基于百度OCR识别提取各类医疗票据/单据字段信息的技术能力,我们共同首创的端到端关系识别模型,整个质检分类准确率可达到97%,实际复杂生产环境中的结构化识别准确率可达86%,大大节约了人力成本,同时显著提升了理赔业务效率。”
北京融汇金信信息技术有限公司创始人罗彤从金融服务的角度发表了自己的看法,他讲到:“金融主要做的两件事其实就是,需要大量数据进行预测,以及大量文档、图片等信息进行客户服务。而百度OCR提供的解决方案,可以让我们把数据和知识打通,解决人工录入信息出错率高、效率低等行业痛点的同时,能够显著节约成本、得到更加精准的预测结果,同时提升整体业务效率。”据悉,在金融服务领域,百度OCR已在银行、保险、证券、信贷、支付等场景应用落地。
除此之外,百度OCR还已广泛应用于财税报销、快递物流、法律政务、交通出行、教育培训、内容审核等众多领域,为企业降本增效,提升用户体验。例如:代账公司借助百度OCR,为中小企业提供智能报账服务,大幅提升业务流程效率;中国移动设计院使用百度OCR对内部报账系统进行智能化改造,20分钟的人工填报流程缩短至1分多钟;在快递物流领域,则可以综合应用OCR、NLP地址识别、语音识别等多项AI能力,提升分拣、配送效率及用户使用体验。
目前,使用百度OCR的用户已超过70万。未来,百度OCR作为百度智能云服务的重要一环,在百度大脑领先技术的支持下,将持续快速迭代,不断优化产品服务,探索更多应用场景,同时赋能更多合作伙伴,助力企业开启智能化升级快速通道,创造更大价值。
 OCR文字识别吾爱专版1.0 绿色版
OCR文字识别吾爱专版1.0 绿色版 IDM UEStudio破解版v21.10.0.32 附注册机
IDM UEStudio破解版v21.10.0.32 附注册机 转易侠OCR文字识别软件3.2.0.2 最新版
转易侠OCR文字识别软件3.2.0.2 最新版 Duplicate Cleaner Pro破解版5.0.13 中文版
Duplicate Cleaner Pro破解版5.0.13 中文版 Kate文本编辑器21.08.3.1486 绿色最新版
Kate文本编辑器21.08.3.1486 绿色最新版 华为鸿蒙OS定制字体(HarmonyOS Sans)全套ttf完整打包版
华为鸿蒙OS定制字体(HarmonyOS Sans)全套ttf完整打包版 大漠插件免费版7.2119 电脑版
大漠插件免费版7.2119 电脑版 Adobe InCopy 2021特别版16.3.1 最新版
Adobe InCopy 2021特别版16.3.1 最新版 熊猫图文识别工具PandaOCR绿色版2.71 最新永久免费版
熊猫图文识别工具PandaOCR绿色版2.71 最新永久免费版 AnyTXT Searcher官方版1.2.481 免费版
AnyTXT Searcher官方版1.2.481 免费版 AIScanner(OCR识别软件)1.0.2免费版
AIScanner(OCR识别软件)1.0.2免费版 字体超市字体设计软件下载1.3.0.0最新版
字体超市字体设计软件下载1.3.0.0最新版 手写模拟器软件免费版1.0 最新版
手写模拟器软件免费版1.0 最新版 盐系可爱风字体合集免费打包版整合版
盐系可爱风字体合集免费打包版整合版 百度通用文字识别工具破解版1.1绿色免费版
百度通用文字识别工具破解版1.1绿色免费版 Qiv_OCR文字识别免费下载吾爱破解2021绿色免费版
Qiv_OCR文字识别免费下载吾爱破解2021绿色免费版 小帅OCR识别工具最新版1.0绿色免费版
小帅OCR识别工具最新版1.0绿色免费版 大学生论文写作助手破解版3.4最新版
大学生论文写作助手破解版3.4最新版 大小: 9.9M
大小: 9.9M







 小说写作助手
小说写作助手 日历模板电子版
日历模板电子版 pdf编辑器免费版
pdf编辑器免费版 支持拼音的输入法软件
支持拼音的输入法软件 PDF阅读器电脑版
PDF阅读器电脑版 字由字体客户端
字由字体客户端
 字魂电脑版
字魂电脑版
热门评论
最新评论